

Data Enrichment Pipeline
Data connectors for system and datasource integration, an extensive collection of data analysis tools, and the ability to easily share data and analyze results.






Build End-to-End Data Pipelines
Integrate, Handle Exceptions, Share Results
Datasource integration from multiple sources. Handle exceptions and outliers automatically. Share data analysis results across your team. All in one workflow.
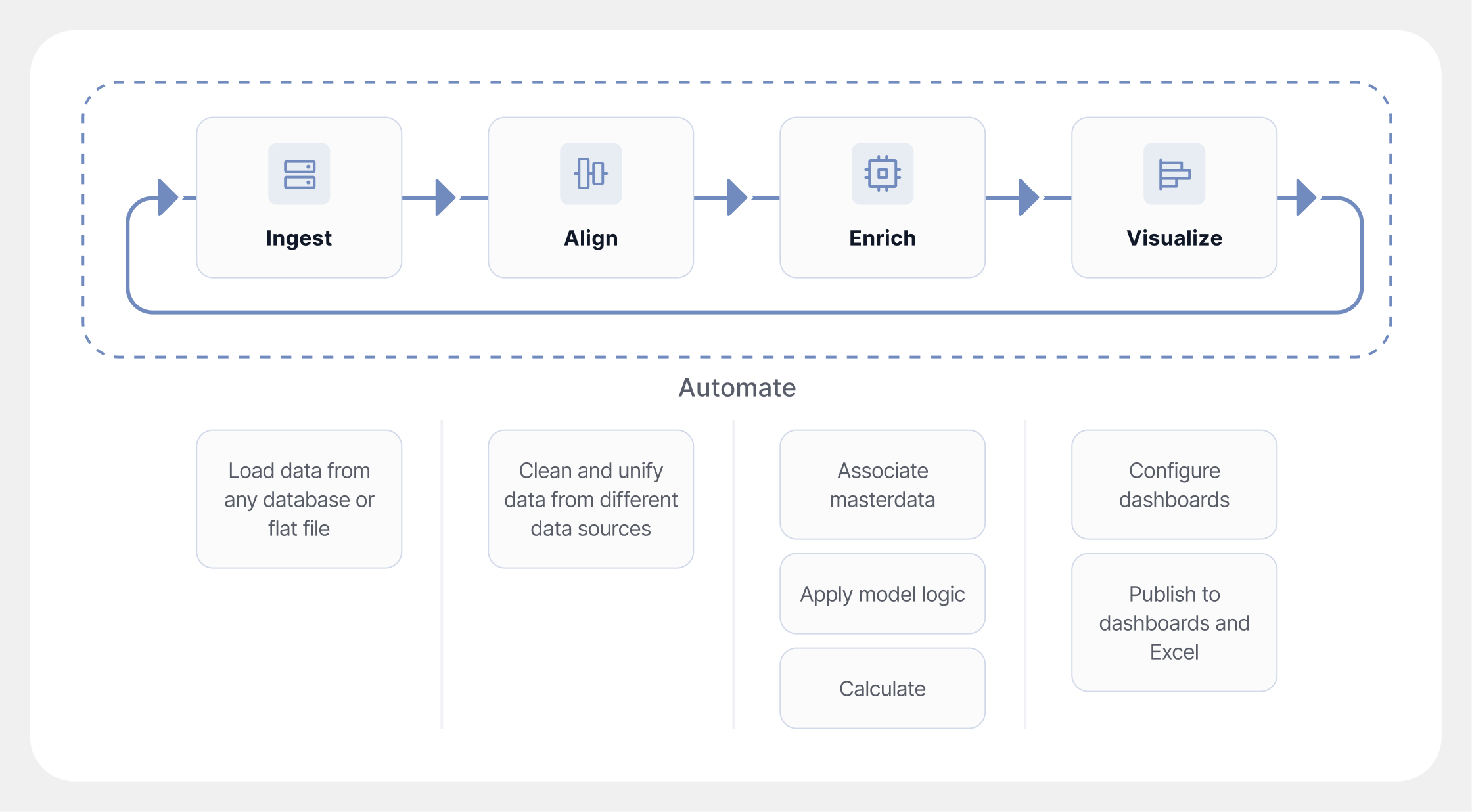
Import, Transform & Export Data
Low-Code, Automated Enrichment
Use a low-code interface to build, run, and automate data enrichment processes. Import from any source, transform with prebuilt steps, and export anywhere.
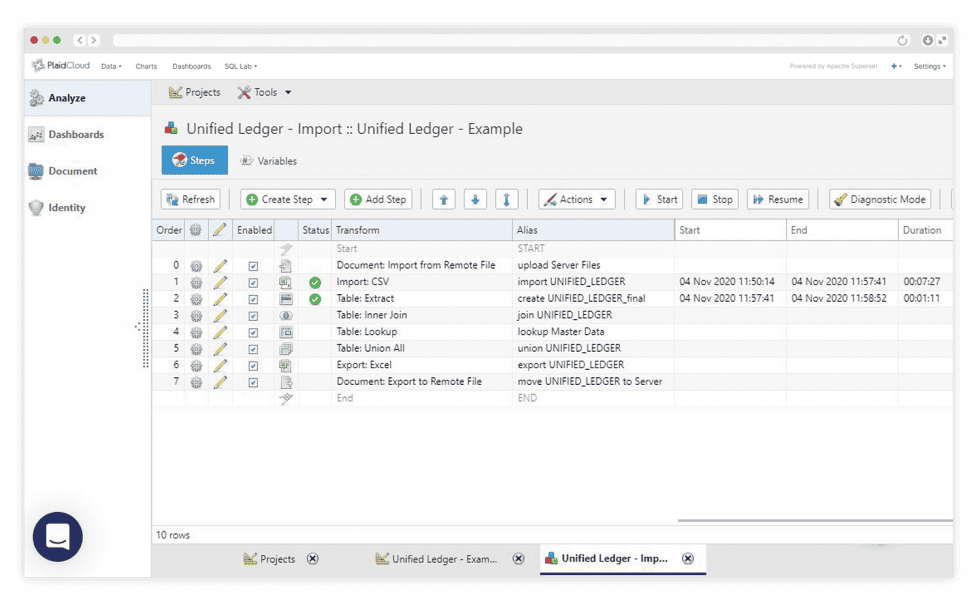
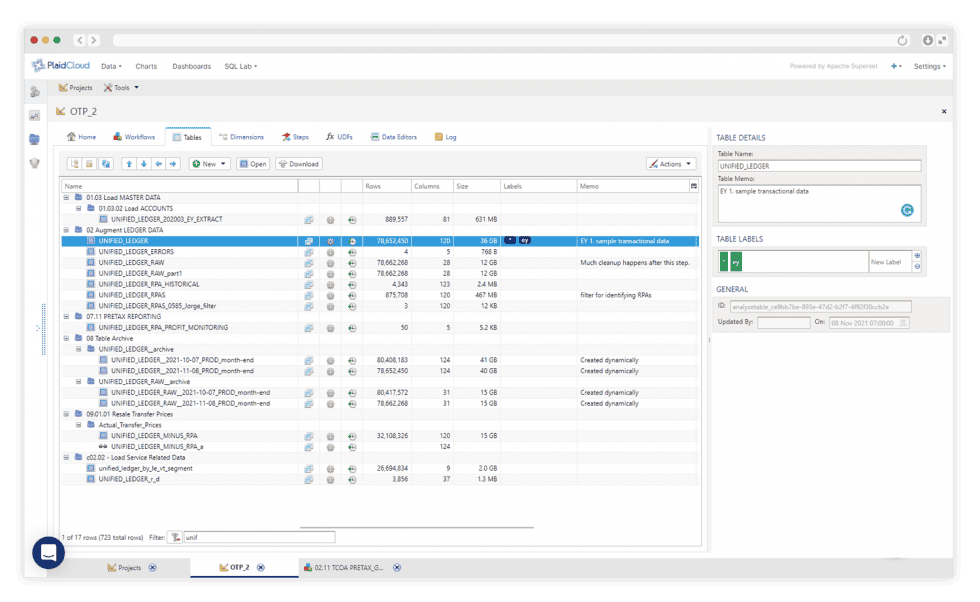
Manage Large Datasets
Greenplum-Powered Scale
PlaidCloud uses Greenplum technology to handle large data efficiently. Billions of rows without the performance cliff of legacy tools.
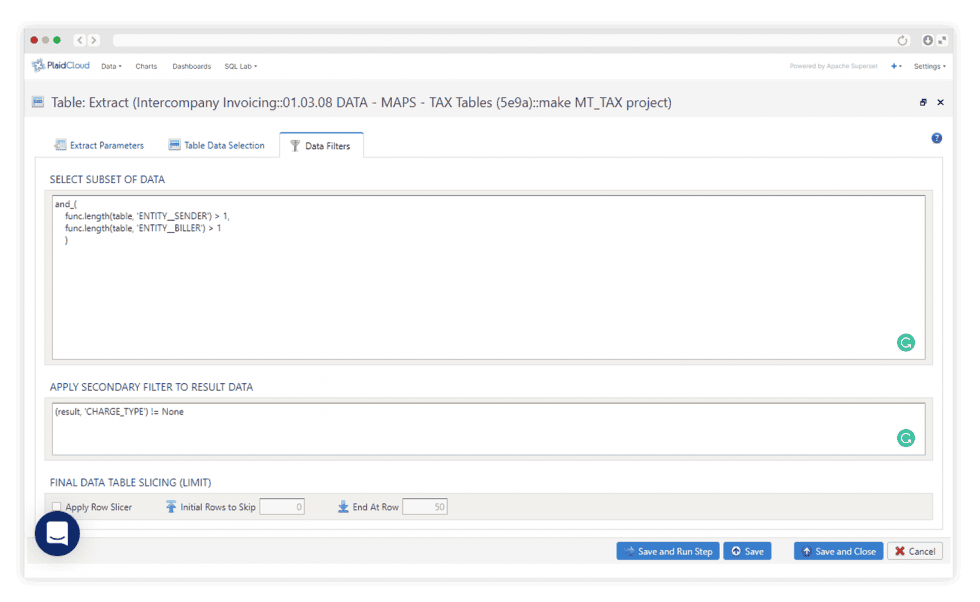
Filter Inbound & Outbound Data
Precision at Every Step
Each transformation step can have inbound and outbound data filters. So every step works only on the rows that matter.
Clean Incoming Data
Sanitize on Import
Data can be sanitized upon import. Trimming, formatting, type coercion, null handling, and more, applied automatically as data arrives.
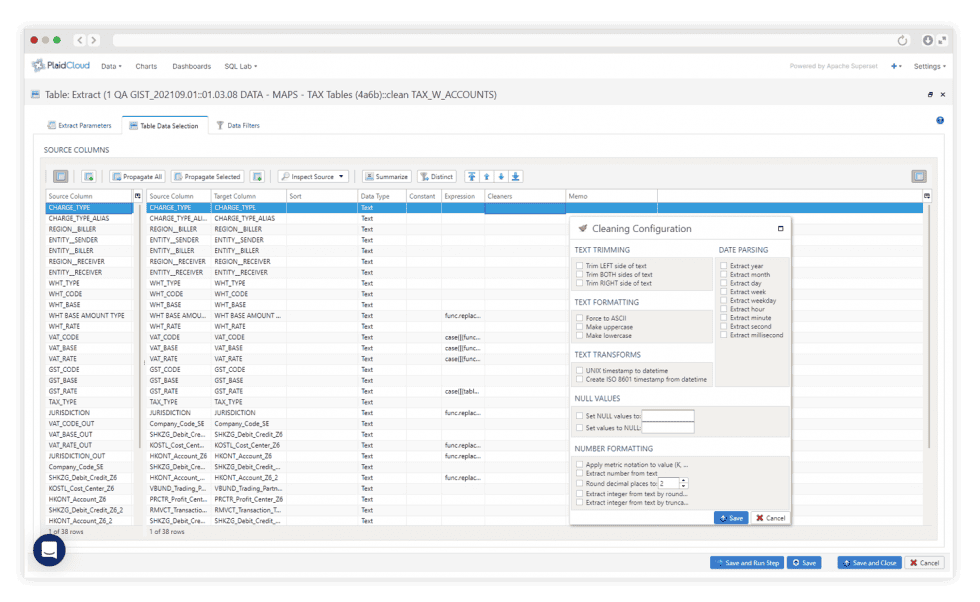
Alter Data With Expressions
Every Field, Fully Transformable
Every field can be transformed with detailed data expressions. And user-defined Python transforms allow custom logic within a workflow when you need it.
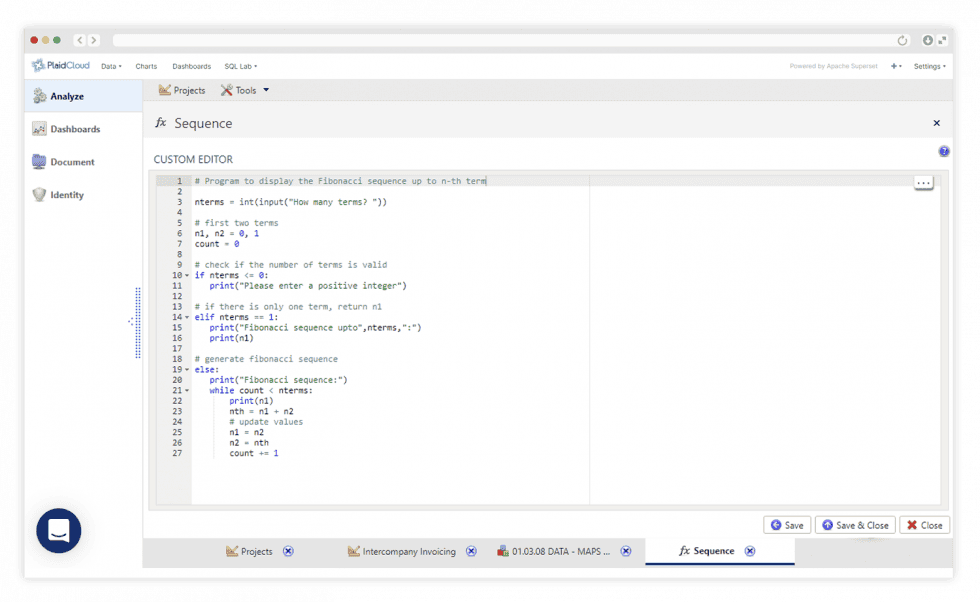
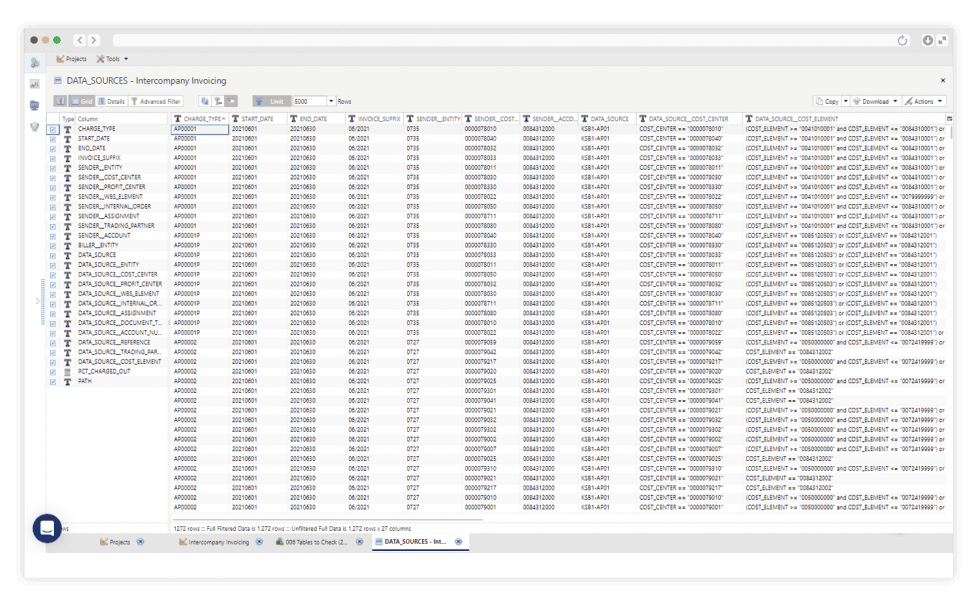
Inspect Database Tables
View Any Dataset With Table Explorer
View any dataset with Table Explorer. Quickly analyze data using interactive grouping and filtering. Then push the results straight into an integrated Apache Superset dashboard.
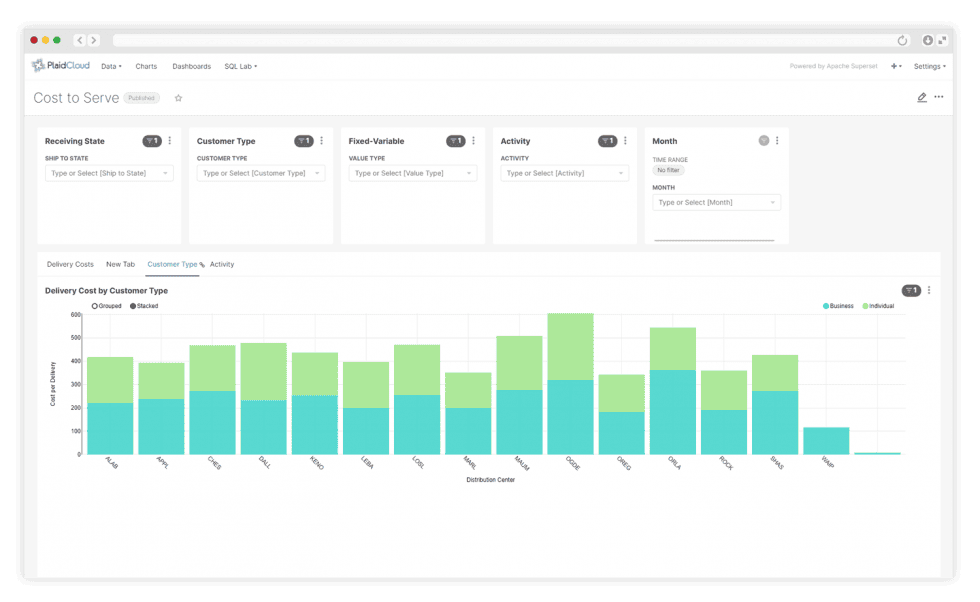
Visualize Data
Integrated Apache Superset
Integrated Apache Superset for data visualization and high-performance dashboarding. Straight on top of your modeled data, no separate BI tool required.
Start with a Conversation
Turn your company's financial and operational data into actionable insights with impact.
Insights
Related Insights

